
With the following words, Microsoft describes its Databricks service:
“Unlock insights from all your data and build artificial intelligence (AI) solutions with Azure Databricks, set up your Apache Spark™ environment in minutes, autoscale, and collaborate on shared projects in an interactive workspace.”
Databricks is an open-source distributed computing framework, and in the past few years, Microsoft has been pushing this new service to a lot of their customers as a useful machine learning environment. Since this service is rather new, however, there are some areas within the service that might not be completely mature yet, and still have room to become more user-friendly. Also, it is not uncommon to sense confusion at companies and within teams regarding how Azure Databricks can be used, and when it should be used in the first place.
In this blog, I will share some insights from my experience regarding when data professionals should consider using Databricks on Azure, and if they do, how to have a nice experience working with it from the start.
When should I use Azure Databricks?
In most of the cases, Databricks comes up as a possible service for companies because it can be used as a simple and complete working environment for data analytics and data science tasks. The premise of it is that developers can quickly start developing code, while not having to worry about setting up the environment in which they work.
Nowadays, a lot of analysts or even stakeholders can read and write SQL. With the use of Azure Databricks, a simple UI is available in which they can run SQL on Spark. This enables them to validate or view data themselves in a fast way without having to install on their own computer.
Another reason that data teams go for Databricks is to use it as a compute target. What this means is that code that is developed anywhere can be executed on a Databricks managed cluster. An example of this workflow is using Azure Machine Learning service (another ML tool from Azure), where data science experiments can be run using a Databricks cluster. Combine this together with the MLFlow capabilities (a way to register experiments and models), and you have a good setup in your ML lifecycle.
Join our team of top-talent data and AI professionals. Click here to view our vacancies.
How do you deploy Databricks on Azure?
Like any other website, Azure Databricks has a UI that can be reached over the internet, and a unique address will be generated for every workspace from your organization.
An Azure Databricks workspace is a logical separation between different files and objects, and it can be viewed as a folder in which you want to organize things that belong together. These workspaces are the first thing one creates when starting with Azure Databricks. Just like most other services, Azure Databricks can be created by the Marketplace in Azure, or, for the more experienced developers, through the Azure CLI.
Databricks makes use of notebooks, which are text fields (called cells) in which you can write and run code. The advantage of this technique is that you can quickly run different pieces of code/functions in a cell. Databricks supports the use of the languages Scala, Spark, Python, SQL and Java.
Even though all these languages are supported, you should think twice if you want to actually use Databricks for projects using any one of these languages. A reason for this is that the Databricks cluster is mostly meant for heavy Spark calculations. If you want to run simple Python scripts using Databricks, the costs are very high for something that can be better run on a much cheaper and simpler VM. You can compare it to using a Ferrari to go grocery shopping around the corner, while you could also take the bike. Both will suffice for what you want to achieve, but the first could be considered as an overkill and more expensive as well.
Don't miss Xomnia's events about the latest trends and news in the world of AI. Click here.
Does Databricks have version control?
With Databricks, the idea is that all the notebooks are shared, and that team members have access to each other's files, which potentially can lead to more and quicker collaboration. While this is an advantage and a reason for people to like working with Azure Databricks, it provides one of the biggest challenges as well. For instance, when team member A is working with multiple files, and team member B is also working on one of the same files, they have to beware that things could go wrong when they alter code without letting the other know.
How do you manage the different versions of the files on Databricks, and how do you know what file is the latest? If File A calls File B, but B is changed while file A is executed, what will be exactly executed then?
From the start, Databricks had integrated version control, but in practice, this didn’t function properly for reasons that go beyond the purpose of this blog post. At the start of 2022, however, a new integrated way for version control was released for public use, and was named “Repos for Git”. While I haven't used it personally yet, at a first glance it looks like an improvement over the previous version, although others say that there is still room for improvement.
Since this wasn’t available before, below I describe another way of working that made it easier to manage version control on Databricks:
Recommended usage of Databricks
So now you might wonder, how should one use Databricks then? My recommendation is to mainly use it as a development environment, in which developers can quickly run first analyses without using their own computer as the compute target. However, if you want to use Databricks in a more structured way, there are few tips to do so.
- Create at least two workspaces: One for DEV/TST and one for ACC/TST. With this setup, you can disable manual changes on ACC/PRD, to make sure the latest approved versions are used in these environments.
- Use databricks-connect: Databricks has a convenient Python library called “databricks-connect”, which enables you to connect the remote databricks cluster by sending your local code to be executed on the cluster. Another advantage of this solution is that since you can develop locally and still have access to the cluster, you then can manage all the version control via your own favourite IDE, such as Visual studio code or Pycharm. By doing so, you will take away the centralized location in which the developers could code along in each other's files within the Databricks UI, but would make the maintainability of the code easier and more prone to errors. With this setup, there is also room for proper CI/CD. This solution does have some limitations, which you can read more about here.
- Use Azure Devops: Since we are talking about Azure Databricks, an obvious solution would be to use Azure Devops, which natively integrates with it. Azure Devops is a service which has a lot of tools such as building and deploying applications, which go hand and in hand with the use of boards and a version control system. You could host the version control of your Azure Databricks code in Azure Devops, and on a merge to acceptance or master, deploy it to those environments using pipelines.
- Use Databricks as a compute environment for analytical tasks: When you have an use case in which a lot of data has to be processed, Azure Databricks is a good option. This solution can scale to the necessary capacity to load that data according to your needs. By using it this way, there are no issues wrt the UI and version control.
A minimal simplified starting point for a complete lifecycle machine learning environment would be the following:
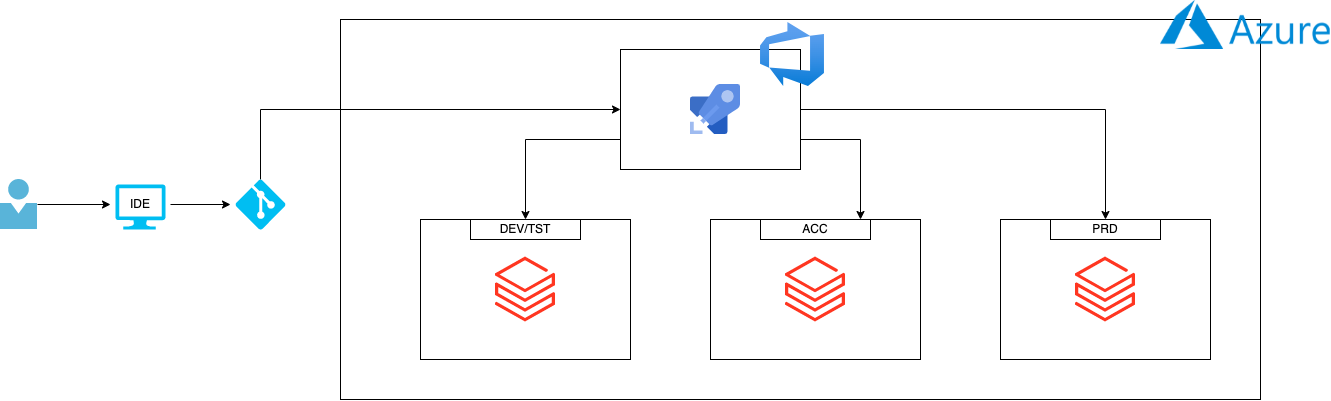
As a developer, you can work within your own IDE using Databricks-connect, and do your version control via git. When a change is pushed to the main branch, this triggers a build pipeline within Azure Devops. That trigger results in the newest code being pushed to the DEV/TST environment. This can be done by using the Databricks CLI, which can place the newest files in the workspace. If the tests come back positive on DEV/TST, the release pipeline will be triggered. This will roll out the changes to the ACC environment. On manual approval, role out the changes to production.
For a better understanding of this product, and in what scenarios it could be used, I recommend reading the Azure reference architecture.
Don't miss Xomnia's latest business cases and blogs. Subscribe to our newsletter.