
When developing a machine learning model, it is very important that the data you feed the model is machine-readable. In other words, the data should be in such a format that your model will be able to detect possible relationships stored in the data. If this is not the case, your model will have a hard time making predictions because it isn’t able to correctly understand the data you’re giving it in the first place.
I encountered this problem at my client Technische Unie when they wanted to improve the search engine on their webshop. With hundreds of thousands of products, a well functioning search engine is crucial.
The data that our team had available to improve the webshop’s search engine was very understandable for humans. However, human-readable data is sadly not an ideal format if you want to practice machine learning. In this blog I’ll take you through the process of transforming this data into a machine-readable dataset, in order to create a model that will improve the webshop’s search experience and increase conversions.
A first approach
The idea for our first model was simple: for every search term ever used we count which of the displayed products was added to the customer’s shopping basket the most. This product should then be displayed as the very first result when someone searches for the same search term in the future. The second most popular product should be in second place and so forth.
This model is very intuitive and provided reasonable results. In my opinion, it’s best practice to start with such simple and understandable models and see how they work. However, we encountered a problem. Not all customers use the same language when searching for a specific product. In fact, there’s an infinite amount of possibilities that customers can use to search for a product!
This creates a weak spot in the above model, as for each search term ever used we count how often the displayed products are added to the user’s cart. Since there are so many different search terms, the data becomes quite sparse. That means that per individual search term, we observe just a small amount of products that were added to a user’s cart.
Moving towards a more machine-readable format
We wanted therefore wanted to use a more advanced model, capable of detecting complex relationships between search terms and products. Once the model has mapped these relationships, it should then be able to predict - based on the used search term - which products (out of all possible products) have the highest chance of being added to the user’s cart.
In order to implement such a model, I understood that I had to transform the data I was feeding my computer. Products and search terms are concepts that are very understandable for us humans. However, for a computer these concepts are meaningless. Therefore, I had to transform them in such a way so that the computer could interpret them as well. In other words, I had to make the data more machine-readable.
An introduction to word2vec
We decided to use a method derived from NLP (Natural Language Processing) called word2vec. However, we would use it in an entirely different manner. The word2vec model is created to take in lots of sentences (for example a book), analyze them, and return a vector for each word in the book. This vector is simply a sequence of numbers. The beauty behind this algorithm is that words with a similar meaning are given a similar vector. For example, one can expect that the words “man” and “woman” are turned into a similar vector, because they represent a similar kind of concept (a human).
The model does this by analyzing all the sentences it is given, and checking which words occur in similar places. If the model is given two sentences such as “the man is riding a bike” and “the woman is riding a bike”, it sees that the words “man” and “woman” are interchangeable. Thus it learns that both words represent a similar thing.
Representing products as vectors
We have used the same principle, but we’ve applied it in a different way. Instead of feeding sentences of words to the model, we’ve fed the model “sentences” of products. Let me explain. Entering a search term in Technische Unie’s website will give you a list of products. Searching for “battery” for example, gives you 50 different batteries on the first page of results. Each of these batteries has a unique product ID. We put these product IDs in a list and call this our “sentence”. You can view the individual product ids in this sentence as “words”.
Now we observe another searchterm: “battery 5v”. Entering this search term yields us 50 different results, which we’ll see as another “sentence” containing 50 “words”. However, since the search terms are similar, some of the displayed batteries will be the same. Just like the model was able to learn that the words “man” and “woman” represent a similar thing, it can now learn that two batteries represent a similar thing, because they could have been used interchangeably in the “sentences” we’ve provided the model.
Doing this for about 75.000 different sentences (i.e. search term results) the model is able to represent products as vectors. The magical part is now that similar products are represented as similar vectors. When we reduce the dimensionality of these vectors and plot them in a 2-dimensional space, the following scatterplot results.
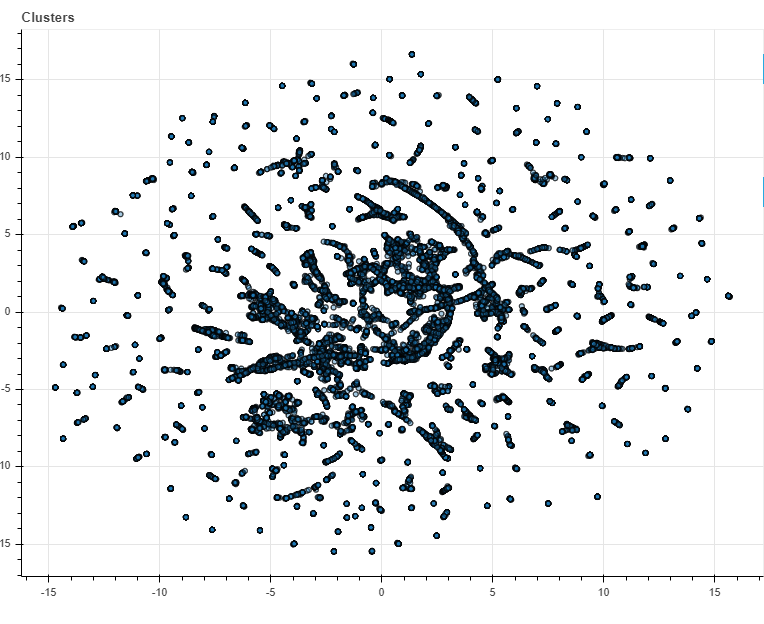
Each dot represents a product. Hovering our mouse over different clusters of products reveals the name of those products. See the below image. It is clearly visible that similar products are given similar coordinates. This tells us that the model has succeeded in learning which products are similar!
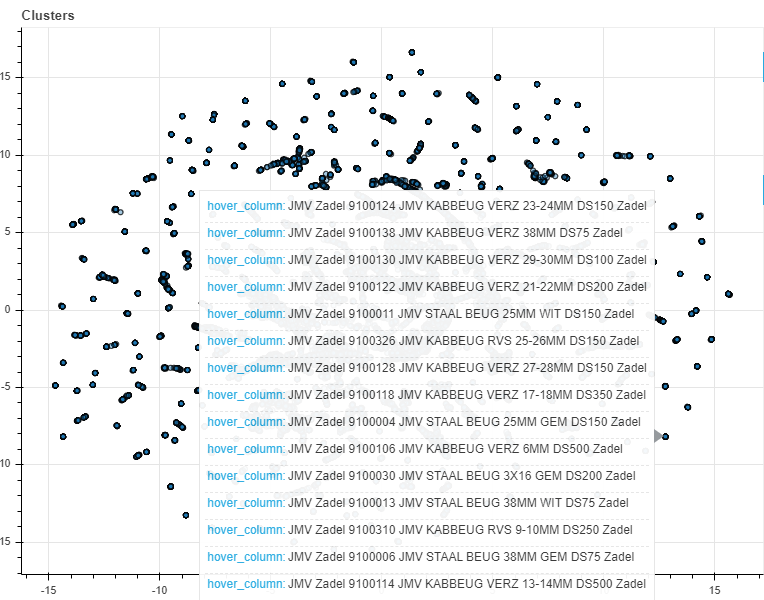
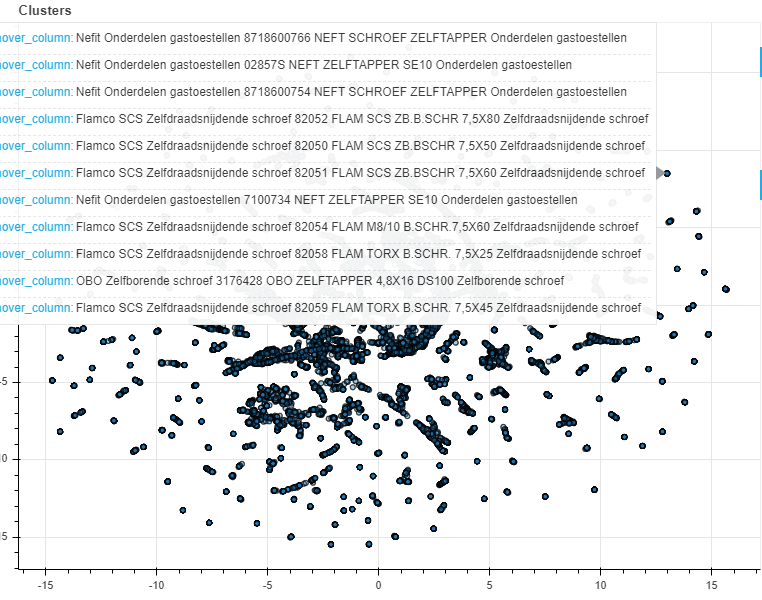
Figure 2: hovering our mouse over one of the clusters of products shows the name of the products in that area. Judging from the fact that the names are very similar, we can conclude that our model succeeded in clustering similar products.
Representing search terms as vectors
Now that we’ve represented our products as machine-readable entities, thereby teaching our computer which products are similar and which products are not, we can continue to do the same thing for our search terms. Remember that each search term is associated with a list of 50 products. Each of these products, however, is now represented as a vector (we’ve chosen to use 100-dimensional vectors). That means that each search term can be represented as a 50x100-dimensional matrix. Applying a dimensionality reduction technique called PCA on such a matrix, results again in a 100-dimensional vector. In this vector, distilled information is contained about the 50 products associated with the search term. We have now represented a search term in a vector.
Plotting these search term vectors in a 2-dimensional space, just as we have done for our product vectors, results in the shown scatterplot.
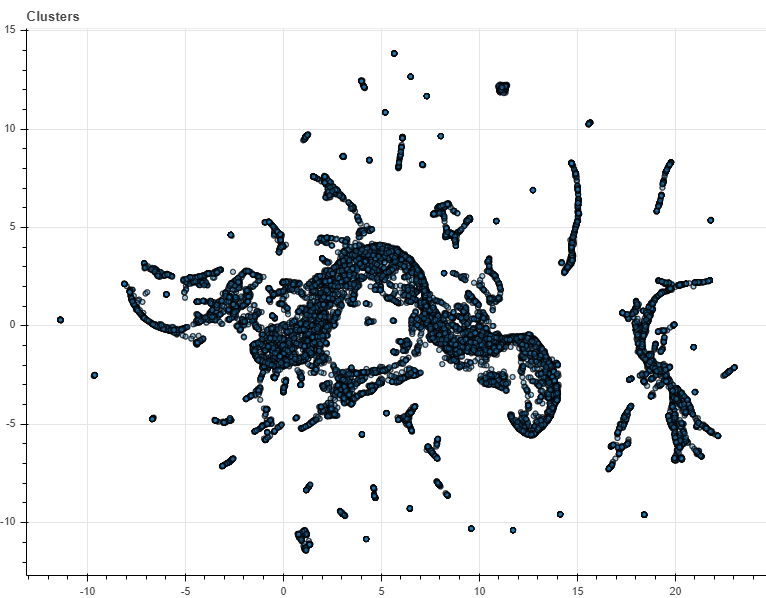
Each dot now represents a search term. Hovering our mouse over the clusters of search terms shows that similar search terms were given similar coordinates. Thus, we can again conclude that the model succeeded in representing similar search terms in similar vectors.
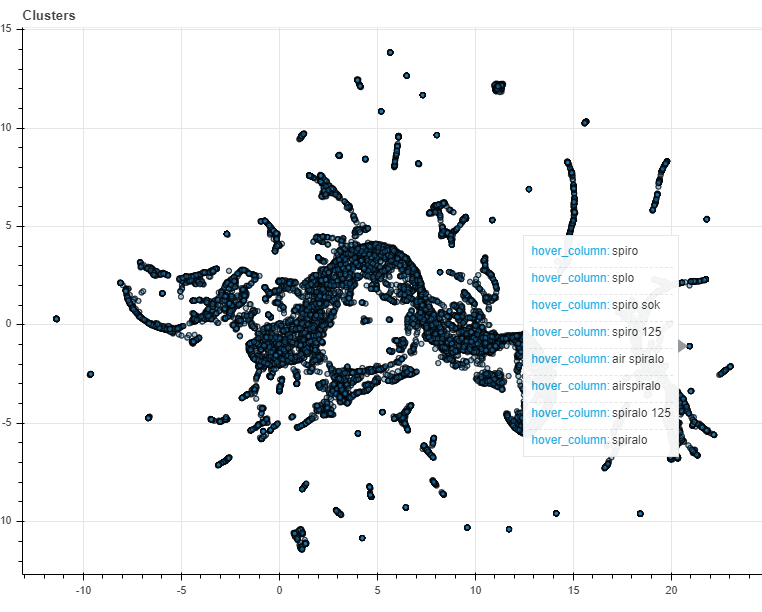
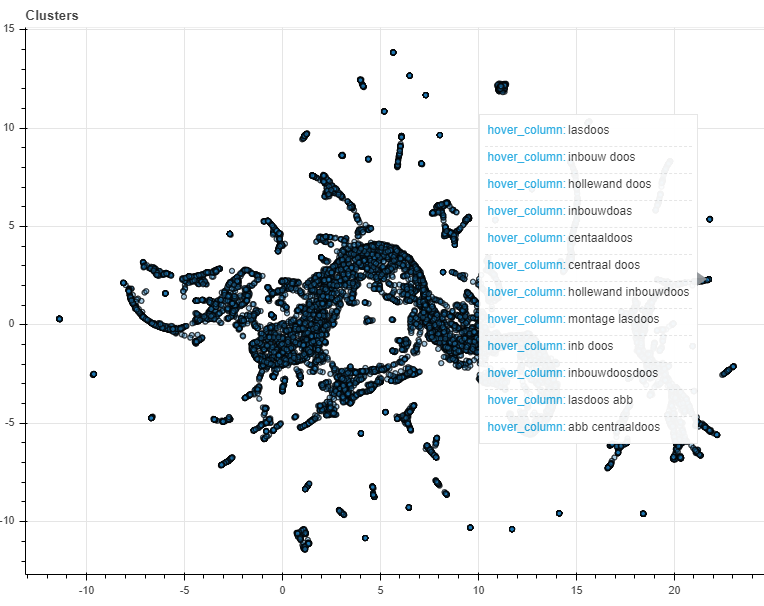
Figure 4: hovering our mouse over one of the clusters of search terms shows that they are very similar. We can thus conclude that our model succeeded in clustering similar search terms.
How to continue
Now that we have represented both our search terms and our products as machine-readable vectors, we have created a useful dataset in which a computer can detect relationships. Remember that our initial goal was to learn - for any given search term - which products have a high chance of being added to the user’s cart. We have achieved our goal as we can now create such a model. That model takes as an input the vectors we’ve just created and from these vectors the model can learn relationships between certain search terms and certain products, telling us which products we should display first when a certain search term is used.
Conclusion
When you want to create a machine learning model, it’s key that you extract as much information out of your dataset as possible. Moreover, your computer needs to be able to correctly understand these data. As discussed in this blog, words and products, which are very readable for humans, have no intrinsic meaning to computers. Translating these to a machine-readable format enabled us to create a model that improved the search engine of Technische Unie’s webshop.
******
This blog was written by Max Bijkerk, during his time as a Xomnia junior data scientist. Our juniors take on challenging projects for our clients, such as this one at Technische Unie. Plus, by on-boarding one of our young professionals, our clients receive access to the knowledge and experience of our entire team of data scientists, engineers, and analytics translators. Learn more about how our juniors can support your data-driven projects.